
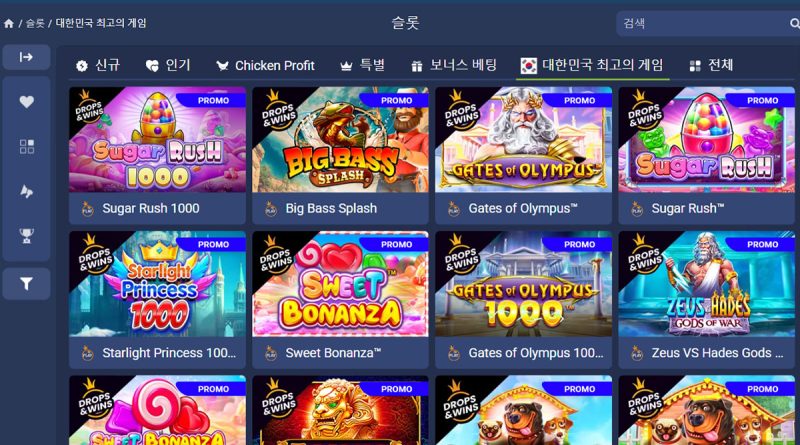
국내 슬롯 커뮤니티 인기 순위 1위인 ‘게이츠 오브 올림푸스’를 비롯한 2026년 프라그마틱 슬롯 게임 TOP10의 공식 환수율(RTP)과 변동성에 대한 가이드, 그리고
스포츠 관련

먹튀 검증업체, 먹튀 보증업체(안전놀이터, 메이저사이트)의 신뢰성 및 활용법
이 글에서는 온라인카지노, 토토사이트의 먹튀 행위를 검증하고, 신뢰할 수 있는 먹튀 보증업체(안전놀이터/메이저놀이터) 목록을 추천한다는 먹튀 검증업체의 신뢰성 및 활용법에 대해서
카지노 관련
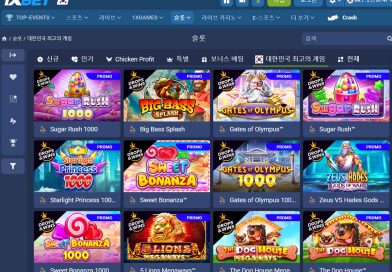
인기 프라그마틱 슬롯 게임 TOP10 – 지원하는 사이트 3곳
국내 슬롯 커뮤니티 인기 순위 1위인 ‘게이츠 오브 올림푸스’를 비롯한 2026년 프라그마틱 슬롯 게임 TOP10의 공식 환수율(RTP)과 변동성에 대한 가이드, 그리고

온라인카지노 후기에서 배우는 먹튀 사례 & 대처방안
최근 해외 불법 도박사이트 운영과 사설 카지노사이트에서 발생하는 먹튀 피해가 급증하면서 각 커뮤니티의 온라인카지노 후기 게시판(DC갤러리, 네이버카페 등)이 난리가 났습니다.